”大数据 spark hadoop“ 的搜索结果
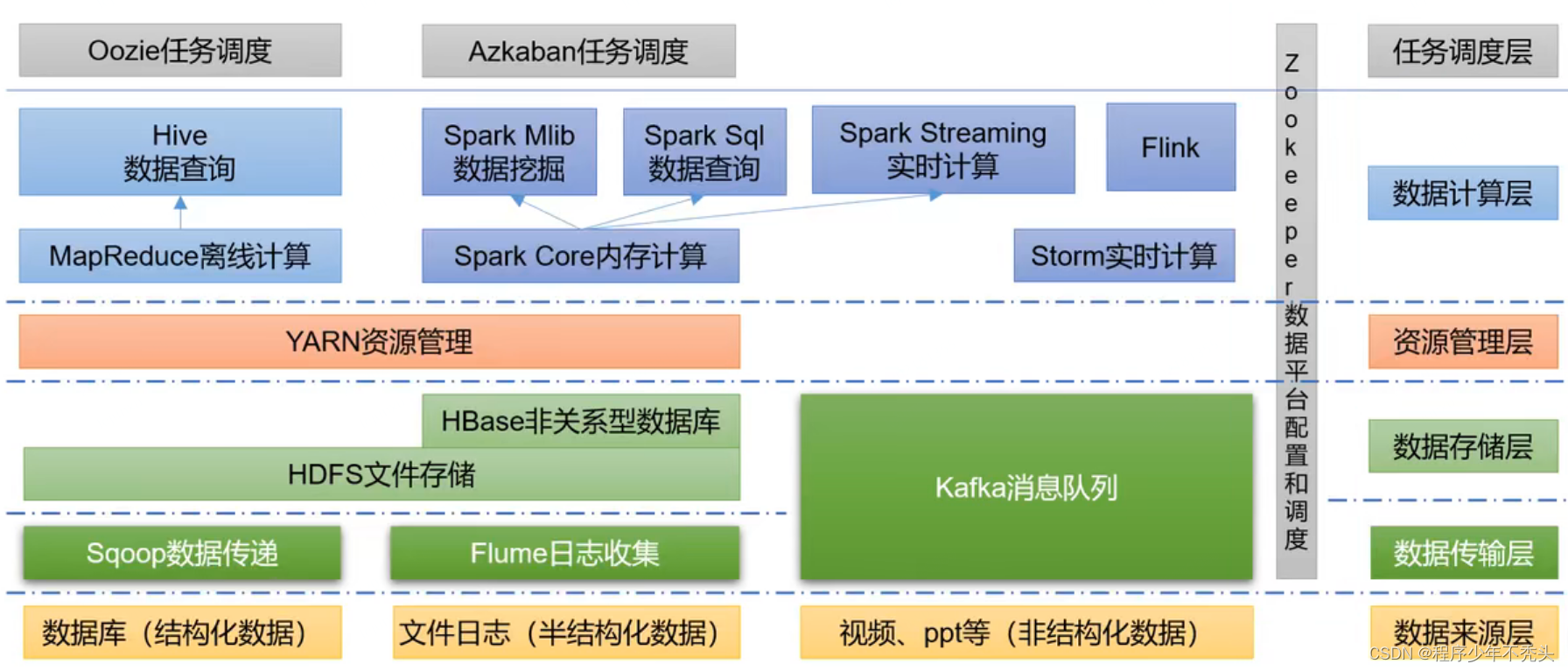
Spark,是一种通用的大数据计算框架,正如传统大数据技术Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。 Spark包含了大数据领域常见的各种计算框架:比如Spark Core用于离线计算,Spark SQL用于交互...
Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到...
实战大数据|Hadoop|Spark|Flink|离线计算|实时计算课程分享下载
Hadoop是一个开源的分布式计算框架,用于处理大规模数据集的存储和分析。它基于Google的MapReduce和Google文件...此外,Hadoop还提供了丰富的生态系统,包括Hive、Pig、Spark等工具和库,使得数据处理更加方便和灵活。

大数据集群之spark2
标签: 大数据
一、环境准备。
大数据Spark面试题汇总,共有79道面试题以及题目的解答 部分题目如下: 1. spark 的有几种部署模式,每种模式特点? 2. Spark 为什么比 mapreduce 快? 3. 简单说一下 hadoop 和 spark 的 shuffle 相同和差异? 5. ...
大数据毕业设计hadoop+spark+hive漫画推荐系统 动漫视频推荐系统 漫画分析可视化大屏 漫画爬虫 漫画推荐系统 漫画爬虫 知识图谱 计算机毕业设计 机器学习 深度学习 人工智能
大数据系列内部培训经典内容,包括大数据系列架构,大数据Hadoop系列、Spark、Hive、Storm、Hbase、Sqoop......
Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到...
随着大数据时代的来临,处理和分析海量数据成为了一项重要的挑战。在大数据系统中由于其存储采用了分布式的架构,计算任务不再是单点的,而是分布式的,是要分发到集群中的各个存储节点上去的,由各个结点计算后汇总...


1.大数据概述1.1.大数据的概念大数据即字面意思,大量数据。那么这个数据量大到多少才算大数据喃?通常,当数据量达到TB乃至PB级别时,传统的关系型数据库在处理能力、存储效率或查询性能上可能会遇到瓶颈,这时考虑...
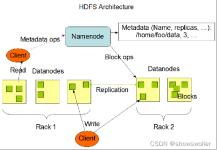
hadoop是一个由Apache基金会所开发的分布式系统基础架构。hadoop的框架最核心的设计就是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算。hadoop具有高容错性,常部署在低廉的硬件...
大数据与HADoop
标签: 大数据
流处理框架:用于对随时进入系统的数据进行实时计算,是一种“无数据边界”的操作方式。Hadoop是一个可靠,可扩展的...数据量越来越大,数据分析的实时性越来越强,数据结果的应用越来越广泛,大数据技术应运而生。
如果有1TB的硬盘,传输速度100MB/s,需要2.5小时读完。
大数据时代Hadoop和Spark技术研究.docx
Hadoop只是一种处理大数据的技术手段。 “大数据”概念在1980年由维克托·迈尔-舍恩伯格及肯尼斯·库克耶 在《第三次浪潮》首次提出,由麦肯锡公司(McKinsey)最早应用。 大数据的特征 1,容量:数据的大小...
大数据Spark企业级实战
标签: spark
《大数据Spark企业级实战》详细解析了企业级Spark开发所需的几乎所有技术内容,涵盖Spark的架构设计、Spark的集群搭建、Spark内核的解析、Spark SQL、MLLib、GraphX、Spark Streaming、Tachyon、SparkR、Spark多语言...
CDH6全套资源安装包、CDH6、大数据平台、hadoop、spark、kafka、大数据技术、数据仓库、hive、hdfs、大数据技术架构、数据平台管理、开源大数据平台、大数据安装包、CDH安装教程
[大数据]Hadoop+Storm+Spark全套入门及实战视频教程-附件资源
HBase、 Java9 、Java10 、MySQL优化 、JVM原理 、JUC多线程、 CDH版Hadoop Impala、 Flume 、Sqoop、 Azkaban、 Oozie、 HUE、 Kettle、 Kylin 、Spark 、Mllib机器学习、 Flink、 Python、 SpringBoot、 Hadoop3.x...
大数据是一系列技术的...Hadoop是一个由Apache基金会所开发的分布式系统基础架构,是用Java语言开发的一个开源分布式计算平台,适合大数据的分布式存储和计算平台。 广义上讲,大数据是时代发展和技术进步的产物...

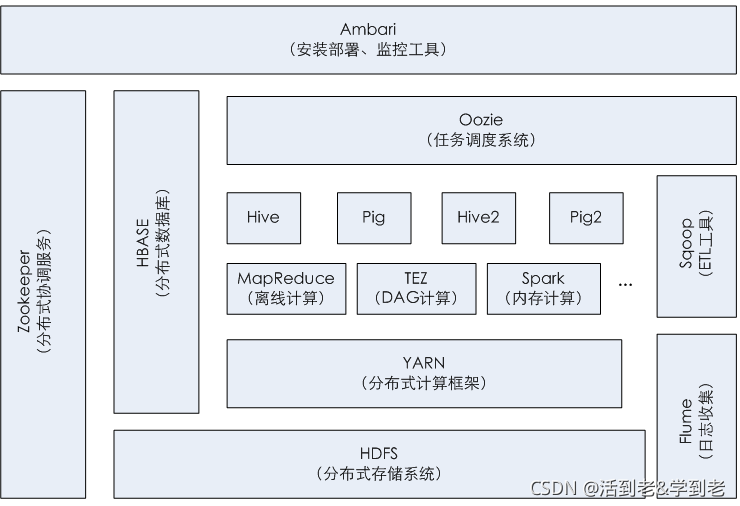
学习着数据科学与大数据技术专业(简称大数据)的我们,对于“大数据”这个词是再熟悉不过了,而每当我们越去了解大数据就越发现有个词也会一直被提及那就是——Hadoop 那Hadoop与大数据有什么关系呢? 所谓...
推荐文章
- element-ui switch开关打开和关闭时的文字设置样式-程序员宅基地
- HttpRequestUtil方法get、post、JsonToPost_httprequestutil.httpget-程序员宅基地
- App-V轻量级应用程序虚拟化之三客户端测试-程序员宅基地
- 实时视频传输方案汇总-java_eclipse视频传输设计-程序员宅基地
- unbantu上python安装步骤_如何在Ubuntu中安装Python 3.6?-程序员宅基地
- NXP NFC Reader Library 移植思路_nxpnfcreader-程序员宅基地
- 分享几个适合新手的C/C++开源项目_c++项目-程序员宅基地
- 自媒体原创检测工具,了解了这个离收获大量粉丝不会远啦!-程序员宅基地
- 使用python对文件夹里的所有表格合并且去重_python 对表格 去重合并-程序员宅基地
- android-Failed to inflate ColorStateList, leaving it to the framework错误-程序员宅基地